Cet article fait partie d’une série présentant en détail les principes du DataOps Manifesto et leur application aux services Data Microsoft. Pour une introduction aux principes DataOps, je vous invite à commencer par cette présentation.
Principe #5 : interactions quotidiennes.
Clients, équipes analytiques et opérations doivent travailler ensemble tous les jours tout au long du projet. J’ai bien dit : « tous les jours » ! Ce qui signifie être prêt à recevoir des feedbacks réguliers et à livrer des versions intermédiaires. Ce qui vous conduira également à terme à automatiser au maximum ces processus (Continuous Integration/Continuous Deployment ou CI/CD, le domaine, parfois obscur et réservé, de nos chers data engineers).
Cet article fait partie d’une série présentant en détail les principes du DataOps Manifesto et leur application aux services Data Microsoft. Pour une introduction aux principes DataOps, je vous invite à commencer par cette présentation.
Principe #4 : il s’agit d’un sport d’équipe.
L’analytique n’est pas l’affaire d’un individu isolé, mais d’une équipe interdisciplinaire combinant data, IT et métiers. Oui, vous avez bien lu : les métiers font partie de l’équipe, au même titre que vos camarades de l’IT. Que l’équipe Data dépende de l’IT ou des métiers, il vous faut obtenir l’adhésion des interlocuteurs métiers et IT pour livrer des outils analytiques de qualité.
Cet article fait partie d’une série présentant en détail les principes du DataOps Manifesto et leur application aux services Data Microsoft. Pour une introduction aux principes DataOps, je vous invite à commencer par cette présentation.
Principe #3 : être ouvert au changement.
Les besoins des utilisateurs évoluent ; il faut les accueillir et les intégrer dans le cycle analytique pour garder un avantage compétitif.
Le premier principe du DataOps Manifesto (si vous n’avez pas encore lu mon article, rattrapage par ici) posait déjà les bases d’une démarche agile : votre modèle sémantique doit être pensé pour le futur : le niveau de granularité de la donnée doit, par exemple, être suffisamment détaillé pour satisfaire les futures demandes.
Cet article fait partie d’une série présentant en détail les principes du DataOps Manifesto et leur application aux services Data Microsoft. Pour une introduction aux principes DataOps, je vous invite à commencer par cette présentation.
Principe #2 : valeur du fonctionnement de l’analyse.
La véritable mesure du succès d’un projet analytique est la valeur des insights livrés, pas seulement le nombre de rapports ou de tableaux. En d’autres termes, le dashboard que vous venez de développer n’a de valeur que s’il est utilisé et qu’il apporte une plus-value à l’utilisateur métier.
Cet article fait partie d’une série présentant en détail les principes du DataOps Manifesto et leur application aux services Data Microsoft. Pour une introduction aux principes DataOps, je vous invite à commencer par cette présentation.
Principe #1 : satisfaire votre client de façon continue.
Le terme clef ici n’est pas « satisfaire » mais bien de façon continue. Après tout, nous savons tous comment satisfaire notre client : nous plier à ses exigences, bâtir rapidement (et pour un moindre coût de développement si possible !) un rapport contenant l’intégralité des données que le client est susceptible d’utiliser pour ses analyses. D’utiliser ou … de ne pas utiliser. Dans le doute, on charge tout dans le modèle sémantique, transformant le modèle en un immense datamart quitte à conserver le contenu complet des tables d’origine.
Si le terme DataOps vous donne des sueurs froides, que vous êtes terrifiés à l’idée de devoir discuter du sujet avec votre manager ou votre équipe, vous êtes donc au bon endroit pour vous y retrouver dans cette jungle impitoyable des buzzwords de la tech.
En 6 années (même un peu plus) de participation aux communautés techniques Microsoft, c’est bien la première fois que je tente l’exercice délicat du bilan des 12 mois écoulés. Et pour le coup, ces 12 derniers mois furent riches en évènements.
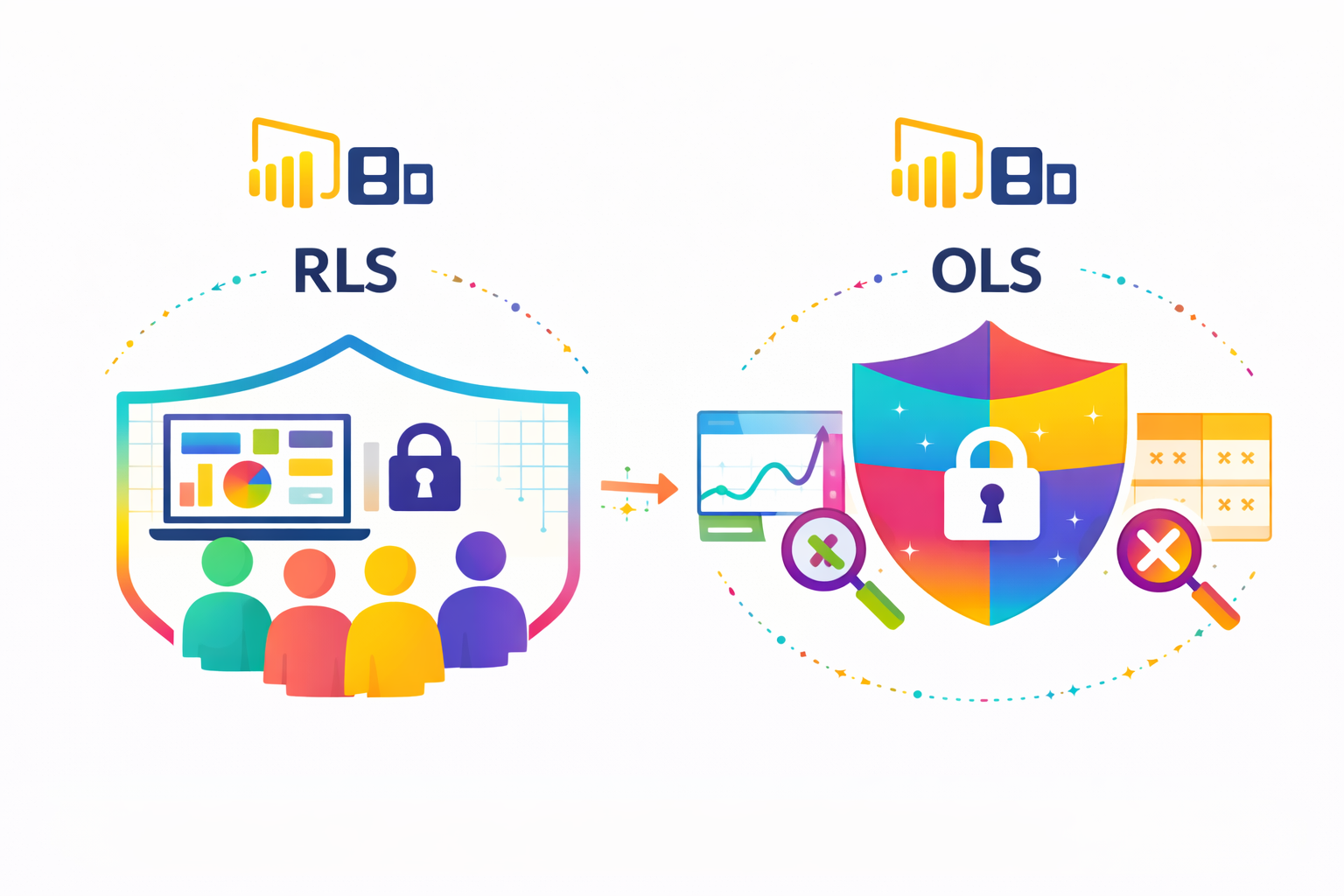
A l’approche de la conférence Ignite ’21, Microsoft multiplie les annonces concernant Power BI. L’une d’entre elle concerne la sécurité des jeux de données et rapports, sujet qui n’avait pas connu d’évolution depuis des années.
Jusqu’à présent, le seul moyen de garantir qu’un utilisateur accède uniquement aux données qu’il est autorisé à voir était de mettre en place des rôles de sécurité en utilisant la Sécurité Niveau Ligne (SNL en français) ou Row Level Security (RLS). Une personne (faisant éventuellement partie d’un groupe AD) est associée à un rôle de sécurité. Chaque rôle filtre les données à travers une formule DAX.
Annoncé durant Microsoft Ignite parmi une longue liste de nouveautés, l’évolution de la tarification de Power BI Premium va probablement démocratiser l’adoption de ce dernier par les entreprises.
Pour rappel, actuellement, Power BI Premium (nous pouvons désormais l’appeler Premium Gen1) donne accès à une capacité dédiée (puissance de calcul et mémoire vive) ainsi qu’à de nombreuses fonctionnalités exclusives. Le coût de la licence la moins chère (P1, si on parle d’une utilisation « full SaaS » de Power BI) réserve le Premium à des organisations ayant au moins 500 utilisateurs potentiels.
Le 26 mars 2020, Microsoft a annoncé la preview publique du read/write XMLA endpoint dans les capacités Power BI Premium. Pour bon nombre d’entre vous, la notion d’endpoint XMLA est probablement inconnue. Mais l’arrivée d’un tel concept dans Power BI révolutionne l’utilisation du service.